Abstract
Modeling the face aging process is a challenging task due to large and non-linear variations present in different stages of face development. This paper presents a deep model approach for face age progression that can efficiently capture the non-linear aging process and automatically synthesize a series of age-progressed faces in various age ranges. In this approach, we first decompose the long-term age progress into a sequence of short-term changes and model it as a face sequence. The Temporal Deep Restricted Boltzmann Machines based age progression model together with the prototype faces are then constructed to learn the aging transformation between faces in the sequence. In addition, to enhance the wrinkles of faces in the later age ranges, the wrinkle models are further constructed using Restricted Boltzmann Machines to capture their variations in different facial regions. The geometry constraints are also taken into account in the last step for more consistent age-progressed results. The proposed approach is evaluated using various face aging databases, i.e. FG-NET, Cross-Age Celebrity Dataset (CACD) and MORPH, and our collected large-scale aging database named AginG Faces in the Wild (AGFW). In addition, when ground-truth age is not available for the input image, our proposed system is able to automatically estimate the age of the input face before aging process is employed.
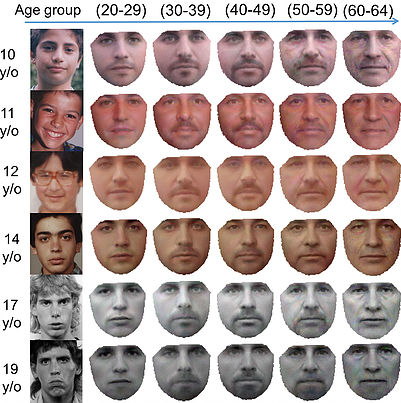
Age Progression
Age Progression in-the-wild
Age Regression
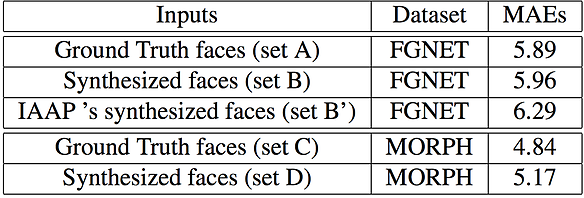
Age Accuracy of Age-progressed faces
C. N. Duong, K. Luu, K. G. Quach and T. D. Bui, "Longitudinal Face Modeling via Temporal Deep Restricted Boltzmann Machines", IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Vegas, Jun. 2016.
C. N. Duong, K. Luu, K. G. Quach and T. D. Bui, "Deep Appearance Models: A Deep Boltzmann Machine Approach for Face Modeling", IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 2015. (under review)
C. N. Duong, K. Luu, K. G. Quach and T. D. Bui, "Beyond Principal Components: Deep Boltzmann Machines for Face Modeling", IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, Jun. 2015.
Citations